One night last year our engineering team was woken up by a multiple-alarm fire, our CPU and memory spiking off the chart. At first we couldn’t believe it—we thought there must be an issue with our monitoring system. But the spikes we were seeing were real. Somehow, without any warning, around 10,000 people were trying to take a test on CodeSignal—at the exact same time.
After the dust settled, we realized that one of our customers had organized a new kind of hiring campaign. Unbeknownst to us, they’d asked thousands of different engineering candidates in different cities to log into CodeSignal at a precise time and take the same assessment.
Over the next few months, this scenario actually repeated several more times with different customers. But we were prepared, because we’d learned from that first experience and made some major changes to our infrastructure. While an unexpected stress test is never fun, it can be a great opportunity to grow as a team and acquire new skills (like how to write your own load testing tool). In this article, we’ll explain what we’ve improved in our infrastructure and where we’re going next.
Improving database performance
The unexpected stress test led us to improve our database performance in a few areas. First, we had some queries related to issuing tests that were causing CPU spikes under a high load, and we fixed those by adding a new index.
We also had to change our algorithm slightly for registration. When someone makes a new CodeSignal account, we require them to have a unique username. If their desired username is unavailable, we will suggest the first available name by appending numbers on the end (e.g. “alanturing1” if “alanturing” is taken). Our logic of using a regular expression worked fine under normal behavior where only a few people were ever signing up at any given time. But to be able to handle a high number of simultaneous signups, we needed to implement some more optimized logic.
Changing our code execution infrastructure
By far the biggest modification we made was to our code execution infrastructure. We use specialized microservices called coderunners to handle requests when a candidate wants to see the output of their code or check it against test cases. Our initial solution was to have a pool of coderunners that we could scale manually. There are different types of coderunners (for backend tasks, frontend tasks, etc.) and originally each one managed its own request queue. The problem was that when we started getting hundreds to thousands of requests at a time, not only did response times slow down for coderunners with long queues, but some of the coderunners would start failing. When that happened we would lose all the requests in their queues.
Building a load testing tool
To figure out how to optimize performance, we needed to understand what type of load our coderunners could handle. We had load testing for our main site, but hadn’t built it for code execution, since in normal behavior we saw a handful of requests at a time. Now we needed to be able to answer questions like, how long it would take to execute 1,000 requests? We decided to design a really simple tool that anyone on the team could use to do load testing:
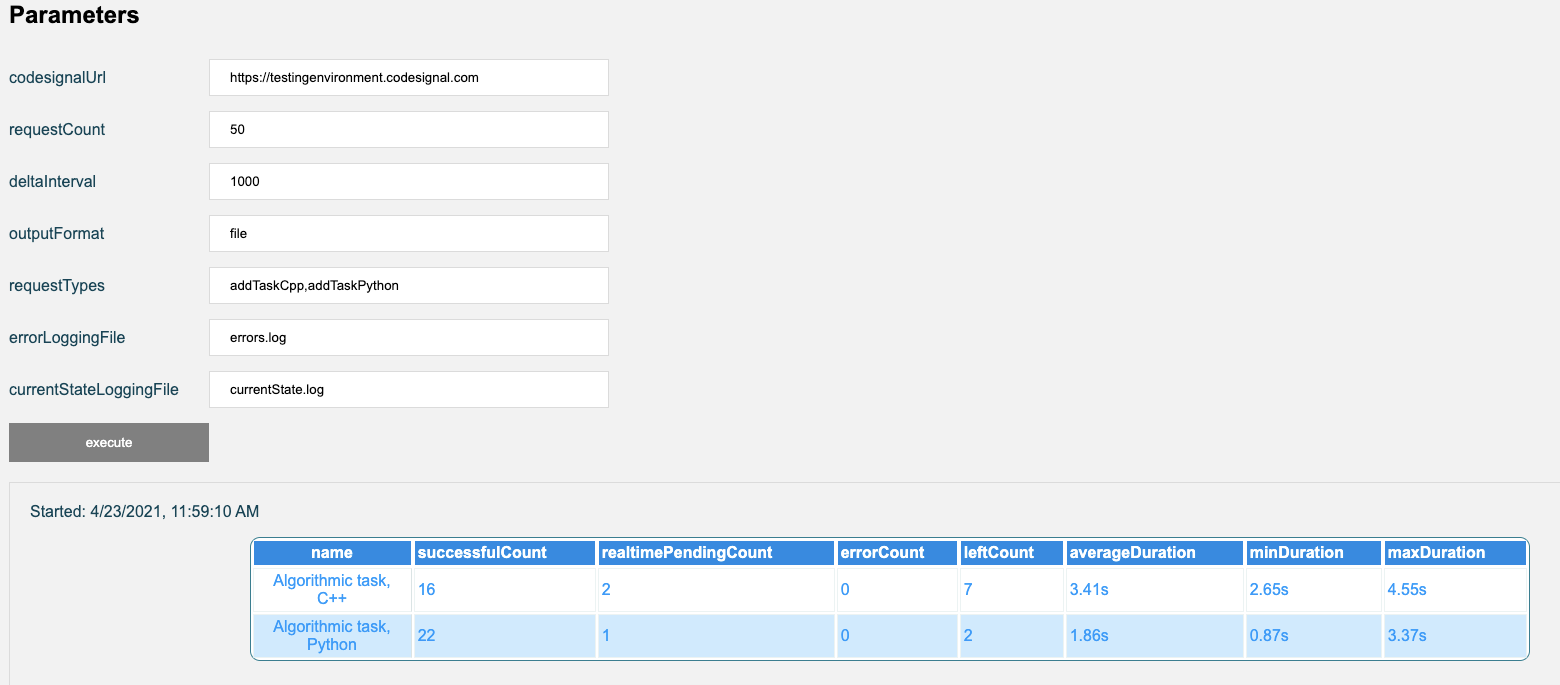
requestCount lets us specify how many requests to fire off at once, with a batch interval in ms controlled by deltaInterval. Certain languages might be faster or slower to execute, so the tool allows us to specify the exact type of task that the coderunners need to handle. We log the output and all the errors to a file. The tool provides statistics such as how long the tasks took to run on average.
This load testing tool helped us figure out where our bottlenecks were and how many coderunners we would need to scale to a certain load. We continue to frequently use the tool to run tests in our staging environment, especially if we are making any changes to our coderunners.
Optimizing our coderunners and request architecture
With the information from our load testing tool, we next began to make major infrastructure changes to how we handle code execution in order to improve our performance under a high load. This involved moving the request queues out of each coderunner and into a centralized queue managed by a matchmaker service. We use Redis to help keep the coderunners and the matchmaker in sync via instant updates on the request statuses. You can read more about how this architecture works in this blog post.
These infrastructure changes took a few months to implement and have paid off in significant ways. Because we’re using a centralized queue, if one of the coderunners fails for some reason, the impact is minimized—requests in the queue won’t be affected. The matchmaker also serves as a load balancer which lets us process each request much faster.
Implementing automatic scaling
We’ve started to work on ways to automatically scale our systems in response to higher loads, so that an on-call engineer doesn’t need to manually spin up more machines. We’re implementing this in several places across our platform to start with.
Automatic scaling for coderunners
Coderunners are highly custom containers for executing user code in an isolated environment. Rather than use a cloud provider like AWS or Galaxy, we built a system called rundash for creating, deploying, and managing coderunners. So while cloud providers come with built-in support for auto-scaling, we’ve had to build this capability into rundash from scratch.
We’ve currently implemented automatic scaling for several types of coderunners (for example, the ones that handle our free-coding tasks) and we’re working on adding more. It’s been an interesting challenge. Rundash has a lot of complicated logic for generating specific types of coderunners for the different tasks they are designed to handle. For example, we have coderunners for frontend tasks and others for backend. Some tasks like machine learning on large datasets require high-CPU coderunners that are very fast but have a cost tradeoff.
Another challenge, and part of the reason we needed to implement custom scaling, is that we can’t just rely on standard performance metrics to decide which coderunners to scale. In some cases the number of sessions and CPU/memory usage might look OK, even as the overall time to complete a run request is increasing. So we need to focus on always minimizing the roundtrip time for code execution, which is what our end users care about as well.
Automatic scaling for proctoring
Proctoring is one of the most data-intensive operations that we do on our system, requiring us to stream video, audio, and screen data for the length of the test. During some of the simultaneous recruiting events we saw last year, we had a load of 10x what we normally get on our proctoring microservice. Learning from that experience, where we had to do some late-night live scaling, we knew we wanted to prioritize making our proctoring automatically scalable.
We’ve now rebuilt the way we handle proctoring on the backend to be able to horizontally scale across multiple containers. We use Galaxy for hosting the infrastructure for this, so we’re able to turn on Galaxy’s auto-scaling feature and have confidence that we’ll be able to handle a higher load.
Future improvements
We’ve learned a lot from our unexpected stress test last year, and while we’ve made many optimizations, there are still areas where we can improve. For example:
- Building better load testing tools for all parts of our system. We’ve built load testing tools for our coderunners and some parts of our platform that have really helped us identify bottlenecks. Now, we want to extend these tools to all parts of our platform.
- Autoscaling more of our systems, such as our remaining coderunners on rundash or other microservices across our platform where we can use Galaxy’s standard auto-scaling feature.
- Improving our alerts system. We’re using Opsgenie to send our engineers notifications in the case of urgent issues, like CPU spikes or the queue being too long for coderunners. However, we’re working on enabling more fine-grained alerts across our entire site.
- Setting up an on-call system. Right now we have engineering owners responsible for different parts of our codebase. Since our team is international and spread across timezones, there is always someone available to respond to issues. Still, we would like to make this system even better.
To help us with these improvements, we currently have two Site Reliability Engineer roles open at CodeSignal! You would be joining a talented, diverse team on a mission to decrease hiring bias and build the world’s best technical interview experience. Check out our careers page here.
Eduard Piliposyan, Director of Engineering, manages CodeSignal’s Europe Engineering team. He leads engineering projects with a high focus on infrastructure and performance optimizations.