Are you captivated by the power of data to solve problems and drive decisions? If so, a career in data science might be an ideal path for you. As a data scientist, you will uncover patterns and predictions that optimize business processes and pave the way for pioneering innovations.
With rising demand for data scientists in sectors such as healthcare and finance, it pays to land a data science role. According to Glassdoor, the average salary for a data scientist in the US is $154,655 per year. But, getting hired for this role can be competitive and challenging. This guide is designed to support your interview preparation goals through 30 job-relevant practice questions, covering everything from basic concepts to advanced scenarios typical of senior roles.
Get ready to ace your next interview with our comprehensive guide. Whether you’re applying for a junior-level position or aiming for a leadership role, these questions will prepare you to show off your data skills and impress your future employers.
Jump to a section:
- Basic level questions
- Advanced level questions
- Technical data science interview questions
- Python data science interview questions
- Pandas data science interview questions
- R data science interview questions
- SQL questions for data science interviews
- Big data questions for data science roles
- Machine learning data science questions
- AI and automation data science questions
- Data collection and data processing questions
- Statistics and probability interview questions
- A/B testing questions for data science interviews
- Non-technical data science interview questions
- Next steps & resources
Basic level questions
When preparing for an entry-level data science interview, you’ll encounter questions that cover the fundamental concepts of data science basics. These questions aim to assess your foundational knowledge and understanding of core principles essential to the field.
Here are some topics that basic-level interview questions may cover:
- Statistical analysis: Understanding descriptive and inferential statistics.
- Data manipulation: Basic methods of cleaning, sorting, and organizing data.
- Programming skills: Familiarity with Python or R for simple tasks.
- Problem solving: Demonstrating logical thinking through hypothetical data scenarios.
Learning tip: Looking to build your technical skills in data science before interviewing for a role? CodeSignal Learn’s Journey into Data Science with Python learning path takes you through using popular data science libraries like NumPy and pandas, creating data visualizations, and using ML algorithms in 7 practice-based courses.
Advanced level questions
In a senior-level data science interview, you’ll be faced with advanced questions designed to challenge your expertise and test your ability to solve real-world data challenges. These questions demand advanced analytical skills and a deep understanding of senior-level data science topics, emphasizing your problem-solving skills and decision-making capabilities. Mastery of these elements is crucial as they allow you to handle intricate analyses and develop innovative solutions that directly impact business outcomes.
Here are some topics that advanced-level interview questions may cover:
- Advanced machine learning: Deep knowledge of algorithms, including supervised and unsupervised learning, neural networks, and ensemble methods.
- Big data technologies: Proficiency in handling large datasets using technologies like Hadoop, Spark, and Kafka.
- Statistical modeling: Detailed discussions on predictive modeling, time series analysis, and experimental design.
- Data architecture: Understanding of how to structure data pipelines and optimize data storage for efficient querying and analysis.
- AI and automation: Insights into the integration of artificial intelligence techniques to automate data processes and enhance predictive analytics.
These topics reflect the sophisticated nature of senior-level roles, where you are expected to lead projects, design data strategies, and provide actionable insights that significantly impact business outcomes.
Technical data science interview questions
In your data science interview, you’ll be tested on a variety of technical skills commonly used in the role. Expect questions that assess your proficiency with querying languages like SQL and programming languages such as Python or R, which are often used for data manipulation and analysis. You’ll likely also discuss how you apply statistical methods and machine learning algorithms as they relate to real-world data challenges.
Python data science interview questions
In your data science interview, expect to demonstrate your Python coding skills through a variety of questions focused on Python for data analysis and scripting. You’ll need to demonstrate your familiarity with essential Python libraries like NumPy, pandas, and Matplotlib, which are critical for manipulating datasets and creating visualizations.
Python data structures
Question: Can you explain how you would use Python lists and dictionaries to manage data in a data science project? Provide an example of how you might implement these structures.
Sample answer: Python lists and dictionaries are fundamental for managing data efficiently in Python scripts. For instance, I often use lists to store sequential data and dictionaries for key-value pairs, which is useful for categorizing or indexing data without using external libraries. An example would be reading raw data from a CSV file line by line, storing each line as a list, and then aggregating counts or other metrics in a dictionary where keys represent categories or unique identifiers from the data.
Difficulty: Basic
Basic Python scripting for data processing
Question: Describe a scenario where you would write a Python script to process and analyze raw text data. What steps would you take in your script?
Sample answer: In a scenario where I need to process raw text data, such as customer feedback, I would write a Python script that reads text files, cleanses the text by removing special characters and stopwords, and then analyzes frequency of words or phrases. The script would start by opening and reading files using a loop, then apply transformations to clean the text using Python’s string methods. Finally, I would use Python’s built-in functions or a simple loop to count occurrences of each word or phrase, storing the results in a dictionary for later analysis or reporting.
Difficulty: Basic
Data visualization with matplotlib
Question: Write a Python script using matplotlib to create a bar chart that compares the average monthly sales data for two years. The sales data for each month should be represented as two bars side by side, one for each year. Include labels for each month, add a legend to differentiate between the two years, and title the chart ‘Comparison of Monthly Sales’.
Sample answer:
import matplotlib.pyplot as plt
# Sample data
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
sales_2020 = [200, 180, 240, 300, 280, 350, 370, 360, 390, 420, 450, 470]
sales_2021 = [210, 190, 250, 310, 290, 360, 380, 370, 400, 430, 460, 480]
# Creating the bar chart
x = range(len(months)) # the label locations
width = 0.35 # the width of the bars
fig, ax = plt.subplots()
rects1 = ax.bar(x, sales_2020, width, label='2020')
rects2 = ax.bar([p + width for p in x], sales_2021, width, label='2021')
# Add some text for labels, title, and custom x-axis tick labels, etc.
ax.set_xlabel('Month')
ax.set_ylabel('Sales')
ax.set_title('Comparison of Monthly Sales')
ax.set_xticks([p + width / 2 for p in x])
ax.set_xticklabels(months)
ax.legend()
# Function to add labels on bars
def autolabel(rects, ax):
for rect in rects:
height = rect.get_height()
ax.annotate('{}'.format(height),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom')
autolabel(rects1, ax)
autolabel(rects2, ax)
plt.show()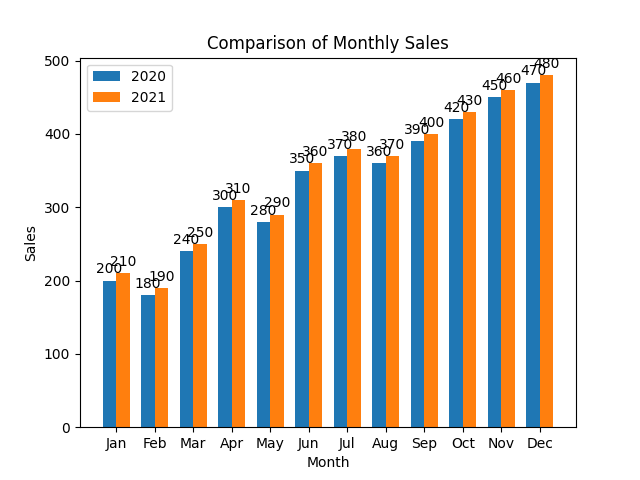
Difficulty: Advanced
Advanced data structures and algorithms
Question: Write a Python function that takes a list of integers and returns a new list with only the unique elements from the original list, but in the same order they first appeared. You should not use any additional libraries like pandas or numpy.
Sample answer:
def unique_elements(nums):
seen = set()
unique = []
for num in nums:
if num not in seen:
unique.append(num)
seen.add(num)
return unique
# Example usage
print(unique_elements([1, 2, 2, 3, 4, 3, 1, 5]))Difficulty: Advanced
Learning tip: For more Python practice questions, check out our guide to preparing for a Python interview.
Pandas data science interview questions
Pandas is a powerful Python library for data manipulation and analysis, providing data structures and functions that make it easy to clean, analyze, and visualize complex datasets efficiently in data science. If the role you’re interviewing for expects you to use the pandas library, you’ll want to be proficient with DataFrames and Series, which are the backbone data structures in pandas. You’ll also want to know how to use pandas for large datasets, as well as its comprehensive tools for data cleaning and manipulation.
Data cleaning with pandas
Question: Given a pandas DataFrame df with columns ‘Date’, ‘Sales’, and ‘Customer_Rating’, write a Python code snippet to clean this DataFrame. Assume there are missing values in ‘Customer_Rating’ and duplicate rows across all columns. Remove duplicates and replace missing values in ‘Customer_Rating’ with the average rating.
Sample answer:
import pandas as pd
# Assuming df is already defined and loaded with data
# Remove duplicate rows
df = df.drop_duplicates()
# Replace missing values in 'Customer_Rating' with the column's mean
df.fillna({'Customer_Rating': df['Customer_Rating'].mean()}, inplace=True)Difficulty: Basic
Advanced data manipulation with pandas
Question: You have a pandas DataFrame df containing three years of hourly sales data with columns ‘Date_Time’ (datetime) and ‘Sales’ (float). Write a Python code snippet to resample this data to a weekly format and compute the total sales and average sales per week.”
Sample answer:
import pandas as pd
# Assuming df is already defined and loaded with data
# Ensure 'Date_Time' column is in datetime format
df['Date_Time'] = pd.to_datetime(df['Date_Time'])
# Set 'Date_Time' as the DataFrame index
df.set_index('Date_Time', inplace=True)
# Resample data to weekly, calculate sum and mean of 'Sales'
weekly_sales = df.resample('W').agg({'Sales': ['sum', 'mean']})
# Renaming columns for clarity
weekly_sales.columns = ['Total_Weekly_Sales', 'Average_Weekly_Sales']Difficulty: Advanced
Learning tip: Want more practice using pandas? Check out the Deep Dive into NumPy and Pandas learning path in CodeSignal Learn, created specifically for data scientists.
R data science interview questions
R is a programming language and software environment specifically designed for statistical computing and graphics, widely used in data science for data analysis, modeling, and visualization. If the role you’re applying for expects you to use R, you should be comfortable with R’s syntax, common functions, and packages such as ggplot2 and dplyr, which are useful for data manipulation and creating insightful graphical representations.
Data manipulation with dplyr
Question: Using R and the dplyr package, write a code snippet to filter a dataframe df containing columns ‘Age’, ‘Income’, and ‘State’. You need to select only those rows where ‘Age’ is greater than 30 and ‘Income’ is less than 50000. Then, arrange the resulting dataframe in descending order of ‘Income’.
Sample answer:
library(dplyr)
# Assuming df is already defined and loaded with data
result <- df %>%
filter(Age > 30, Income < 50000) %>%
arrange(desc(Income))Difficulty: Basic
Creating plots with ggplot2
Question: Write a code snippet using R and ggplot2 to create a scatter plot of df with ‘Age’ on the x-axis and ‘Income’ on the y-axis. Color the points by ‘State’ and add a title to the plot.
Sample answer:
library(ggplot2)
# Assuming df is already defined and loaded with data
ggplot(df, aes(x=Age, y=Income, color=State)) +
geom_point() +
ggtitle("Scatter Plot of Age vs. Income Colored by State")Difficulty: Basic
Complex data manipulation and visualization in R
Question: You are provided with a data frame in R named sales_data, containing columns Year, Month, Product, and Revenue. Write an R script to calculate the monthly average revenue for each product over all years and create a line plot of these averages over the months. Ensure that each product has a unique line with different colors and include a legend to identify the products.
Sample answer:
library(dplyr)
library(ggplot2)
library(plotly)
# Assuming sales_data is already defined and loaded with data
# Calculating monthly average revenue for each product over all years
monthly_averages <- sales_data %>%
group_by(Product, Month) %>%
summarise(Average_Revenue = mean(Revenue, na.rm = TRUE)) %>%
ungroup()
# Creating a line plot
p <- ggplot(monthly_averages, aes(x = Month, y = Average_Revenue, color = Product, group = Product)) +
geom_line() +
labs(title = "Monthly Average Revenue by Product",
x = "Month",
y = "Average Revenue") +
scale_x_continuous(breaks = 1:12, labels = month.name[1:12]) + # assuming Month is numeric 1-12
theme_minimal() +
theme(legend.title = element_blank()) +
guides(color = guide_legend(title = "Product"))
# Display the plot
ggplotly(p)Difficulty: Advanced
Learning tip: Looking to build basic proficiency in R? CodeSignal Learn’s Data Analysis 101 with R learning path is an accessible and engaging introduction to the R programming language relevant to data scientists.
SQL questions for data science interviews
SQL (Structured Query Language) is a programming language used for managing and manipulating relational databases, widely utilized in data science for querying, aggregating, and transforming large datasets to extract insights. When applying for a data science role, you should be prepared to demonstrate SQL skills such as writing complex queries, optimizing query performance, and understanding how to join multiple tables to efficiently extract and analyze data from relational databases.
SQL commands and query optimization
Question: Describe how you would use SQL commands to improve the performance of a data query in a large relational database. What specific techniques would you apply for query optimization?
Sample answer: To improve query performance in a large relational database, I utilize several SQL commands and optimization techniques. First, I make use of ‘EXPLAIN’ to understand the query plan and identify bottlenecks like full table scans or inefficient joins. For optimization, I often apply indexing on columns that are frequently used in WHERE clauses and JOIN conditions to speed up data retrieval. Additionally, I use subqueries and temporary tables strategically to simplify complex queries and reduce the computational load.
Difficulty: Basic
Database management
Question: How do you ensure that your SQL queries are both efficient and effective in extracting insights from a relational database? Can you give an example of a complex SQL query you’ve written?
Sample answer: Efficiency in SQL for data science involves writing queries that will run fast and pull the right data to drive insights. I ensure this by understanding the database schema and relationships within the relational database, which helps in writing accurate SQL commands. For example, in a past project, I had to analyze customer behavior across multiple products. I used SQL to join several tables—customers, transactions, and products—while filtering specific time frames and product categories. This involved complex JOIN clauses and WHERE conditions to extract a dataset that accurately represented purchasing patterns, which we then used for further analysis like segmentation and trend identification. For managing databases, I regularly check query performances and refactor them for better efficiency, ensuring that the data extraction process remains robust and reliable for ongoing analysis.
Difficulty: Advanced
Learning tip: Want a refresher on using SQL before your next interview? Journey into SQL with Taylor Swift, on CodeSignal Learn, is a fun, quick, and engaging learning path that uses Taylor Swift’s discography as your database.
Big data questions for data science roles
Data processing with Apache Spark
Question: Using PySpark, write a code snippet to read a large dataset from HDFS, filter out records where the ‘status’ column is ‘inactive’, and then calculate the average ‘sale_amount’ for each ‘product_category’. Output the result as a DataFrame.
Sample answer:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg
# Initialize Spark Session
spark = SparkSession.builder.appName("SalesDataAnalysis").getOrCreate()
# Load data from HDFS
df = spark.read.format("parquet").load("hdfs://path_to_dataset")
# Filter inactive records and calculate average sale amount per product category
active_df = df[df['status'] != "inactive"].drop(columns=’status’)
active_df.groupby("product_category").agg('mean')
# Show the result
result_df.show()
# Stop the Spark session
spark.stop()Difficulty: Advanced
Real-time data processing with Apache Kafka and Spark Streaming
Question: Write a PySpark Streaming application that consumes messages from a Kafka topic named ‘user_logs’, extracts the fields ‘user_id’ and ‘activity’, and counts the number of each activity type per user in real-time. Display the counts on the console as they are updated.
Sample answer:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, from_json
from pyspark.sql.types import StructType, StringType
# Initialize Spark Session
spark = SparkSession.builder \
.appName("RealTimeUserActivity") \
.getOrCreate()
# Define schema for Kafka data
schema = StructType().add("user_id", StringType()).add("activity", StringType())
# Create DataFrame representing the stream of input lines from Kafka
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "user_logs") \
.load() \
.selectExpr("CAST(value AS STRING) as json_str") \
.select(from_json(col("json_str"), schema).alias("data")) \
.select("data.*")
# Count each activity type per user in real-time
activityCounts = df.groupBy("user_id", "activity").count()
# Start running the query to print the running counts to the console
query = activityCounts \
.writeStream \Difficulty: Advanced
Machine learning data science questions
Model selection
Question: How do you decide which machine learning model to use for a specific problem? For instance, how would you approach a dataset predicting customer churn?
Sample answer: When deciding on a model, I start by considering the nature of the data, the problem type (classification or regression), and the interpretability required by stakeholders. Predicting customer churn is a binary classification problem, so I might start with logistic regression for its simplicity and interpretability. I would also consider tree-based models like Random Forest or Gradient Boosting Machines for their robustness and ability to handle non-linear relationships. I typically compare a few models based on their performance metrics like accuracy, ROC-AUC, and F1-score, and validate them using techniques like cross-validation before making a final decision.
Difficulty: Basic
Handling overfitting
Question: What strategies do you employ to prevent overfitting in a machine learning model?
Sample answer: To prevent overfitting, I use several techniques depending on the model and data. First, I might split the data into training, validation, and test sets to monitor and prevent overfitting during model training. Regularization methods such as L1 or L2 regularization are also effective, especially in regression models. For decision trees, I control overfitting by setting limits on tree depth, minimum samples per leaf, and other parameters. And ensemble methods like bagging and boosting can reduce overfitting by building more robust models from multiple learning algorithms.
Difficulty: Advanced
Model evaluation
Question: Describe how you evaluate the performance of a machine learning model. Can you give an example of how you’ve applied these evaluation techniques in a past project?
Sample answer: I evaluate machine learning models using several key performance metrics. For classification tasks, I look at accuracy, precision, recall, F1-score, and the ROC-AUC curve. For regression, I consider metrics like RMSE and MAE. In a past project aimed at predicting real estate prices, I used RMSE to measure the average error between the predicted prices and the actual prices. I also used cross-validation to ensure that the model’s performance was consistent across different subsets of the data. These metrics helped us fine-tune the model iteratively, which led to more reliable predictions.
Difficulty: Advanced
Application of probability in machine learning
Question: How would you use probability theory to improve the performance of a machine learning model? Please explain with an example where you’ve implemented such techniques in past projects.
Sample answer: Probability theory is crucial for understanding and designing machine learning models, especially in classification problems where we estimate the probability of class memberships. For instance, in logistic regression, we use probability to estimate the likelihood that a given input point belongs to a certain class. This helps in assessing the confidence level of the predictions made by the model. In a past project, I improved model performance by integrating Bayesian probability to continually update the model as new data became available.
Difficulty: Advanced
Learning tip: Boost your ML skills before you apply to your next role with CodeSignal Learn’s Journey into Machine Learning with Sklearn and Tensorflow learning path. This series of 5 courses builds your skills in using ML to clean and preprocess data, create features, train neural networks, and more.
AI and automation data science questions
Predictive analytics in AI
Question: Can you describe how you would use AI to improve the predictive analytics process within a company? Specifically, how would AI enhance the accuracy and efficiency of forecasting models?
Sample answer: AI can significantly enhance predictive analytics by incorporating more complex algorithms, such as deep learning, that are capable of identifying non-linear relationships and interactions that traditional models might miss. For instance, I would use recurrent neural networks (RNNs) or LSTM (Long Short-Term Memory) networks for forecasting sales data, as they are particularly good with sequences and can predict based on the historical data trends. Additionally, AI can automate the feature engineering process, using techniques like feature selection and dimensionality reduction to improve model accuracy and efficiency.
Difficulty: Advanced
Learning tip: New to predictive analytics? The Predictive Modeling with Python path in CodeSignal Learn teaches you how to build and refine machine learning models, with a focus on regression models for prediction.
Building an AI-driven data processing system
Question: Write a Python script that uses an AI model to classify text data into categories. Assume you have a pre-trained model loaded as model and a list of text data called text_samples. Use the model to predict categories and print the results.
Sample answer:
# Assuming model is pre-loaded and ready to predict
# and text_samples is a pre-defined list of text data
import numpy as np
# Simulating text_samples list for demonstration
text_samples = ["This is a sample text about sports.", "Here is another one about cooking.", "This one discusses technology."]
# Function to preprocess text (actual preprocessing steps depend on model requirements)
def preprocess_text(texts):
# Example preprocessing: converting list to numpy array for model compatibility
# This could also include tokenization, lowercasing, removing punctuation, etc.
return np.array(texts)
# Preprocessing the text data
preprocessed_texts = preprocess_text(text_samples)
# Predicting categories using the AI model
predictions = model.predict(preprocessed_texts)
# Printing results
for text, category in zip(text_samples, predictions):
print(f'Text: "{text}" - Predicted Category: {category}')Difficulty: Advanced
Data collection and data processing questions
Data collection and management
Question: You are tasked with designing a data collection strategy for a new app that tracks user interactions with various features. What factors would you consider when deciding what data to collect, and how would you ensure the data remains manageable and useful for analysis?
Sample answer: When designing a data collection strategy for the app, I would first identify the key metrics that align with our business objectives, such as user engagement times, frequency of feature use, and user feedback scores. I would ensure that the data collected is both relevant and sufficient to inform decision-making without collecting unnecessary information that could complicate processing and storage. To keep the data manageable, I would implement a schema that organizes data into structured formats and use automation tools to clean and preprocess the data as it comes in. This could involve setting up pipelines that automatically remove duplicates, handle missing values, and ensure data integrity.
Difficulty: Basic
Data cleaning and preprocessing
Question: You receive a dataset containing customer transaction data over the past year. The dataset is incomplete with numerous missing values and some duplicate entries. How would you go about cleaning this data to prepare it for analysis?
Sample answer: To clean the dataset, I would first assess the extent and nature of the missing values. For categorical data, I might impute missing values using the mode or a predictive model, whereas for numerical data, I might use mean, median, or regression imputation, depending on the distribution and the amount of missing data. To address duplicates, I would identify unique transaction identifiers or a combination of variables (like date, time, and customer ID) that can confirm a transaction’s uniqueness. I would then remove duplicates based on these identifiers. After handling missing values and duplicates, I would validate the data for consistency and accuracy, ensuring that all data types are correct and that there are no illogical data entries, such as negative transaction amounts. To do this, I’d use both automated scripts for bulk cleaning and manual checks for nuanced errors. Finally, I’d document the cleaning process to allow for reproducibility and maintain a clean dataset for future analysis.
Difficulty: Basic
Statistics and probability interview questions
Understanding statistical distributions
Question: Could you describe a scenario where a Poisson distribution would be more appropriate to model an event than a normal distribution? How would you apply this in a data-driven decision-making process?
Sample answer: A Poisson distribution is ideal for modeling the number of times an event happens in a fixed interval of time or space when these events occur with a known constant mean rate and independently of the time since the last event. For example, it could model the number of users visiting a website per minute. This differs from a normal distribution, which is used for continuous data and where we’re looking at the distribution of means rather than actual event counts. In a business context, I’d use Poisson to predict customer arrivals or fault rates in a time frame.
Difficulty: Basic
Statistical inference
Question: Imagine you’re tasked with evaluating the effectiveness of two different marketing campaigns. What statistical test would you use to determine which campaign was more successful, and why?
Sample answer: To evaluate the effectiveness of two marketing campaigns, I would use a hypothesis test, specifically an independent samples t-test, if the data is normally distributed. This test compares the means of two independent groups in order to determine whether there is statistical evidence that the associated population means are significantly different. I would set up the null hypothesis to assume no difference between the campaigns’ effects, and the alternative hypothesis to indicate a significant difference. The result would inform whether any observed difference in campaign performance is statistically significant or not.
Difficulty: Basic
Probability
Question: Imagine you are given a standard deck of 52 cards. What is the probability of drawing an ace followed by a king, without replacement? Please explain your steps.
Sample answer: To find the probability of drawing an ace followed by a king from a standard deck of 52 cards without replacement, we start by calculating the probability of drawing one of the four aces from the deck. This probability is 4/52, which simplifies to 1/13. Once an ace is drawn, there are now 51 cards left in the deck, including four kings. The probability of then drawing a king is 4/51. Therefore, the probability of both events happening in sequence is the product of the two individual probabilities: about 0.603%
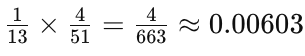
Difficulty: Basic
Advanced statistical methods
Question: Discuss a complex statistical method you have used in your data analysis. How did you decide that this method was the best choice, and what were the outcomes of applying this method?
Sample answer: In a recent project, I applied a mixed-effects model to account for both fixed and random effects in our data, which involved repeated measures from the same subjects. This method was chosen because it allowed us to understand both the fixed effects of the interventions we tested and the random effects due to individual differences. It was particularly useful for dealing with the non-independence of observations, which is a common issue in longitudinal data. The analysis provided insights into how different variables influenced our outcomes over time to guide more tailored interventions.
Difficulty: Advanced
A/B testing questions for data science interviews
Experimental design
Question: Can you walk me through how you would design an A/B test for a new product feature on a website? What steps would you take to ensure the results are statistically significant?
Sample answer: When designing an A/B test for a new product feature, I would start by defining clear metrics of success, such as conversion rate or user engagement time. I would then randomly assign users to two groups, ensuring each has a similar demographic makeup. The test would run long enough to collect sufficient data, using statistical power calculations to determine this duration. Lastly, I’d analyze the results using a hypothesis test—such as a chi-square test or a t-test, depending on the distribution and nature of the data—to determine if there’s a statistically significant difference between the two groups’ performance.
Difficulty: Basic
Interpreting results of an A/B test
Question: After running an A/B test on two different email marketing campaigns, Campaign A resulted in a 15% click-through rate (CTR) while Campaign B resulted in a 10% CTR. What conclusions can you draw from these results, and what would be your next steps?
Sample answer: From the results of the A/B test, it appears that Campaign A performed better than Campaign B. This suggests that the elements or messaging used in Campaign A were more effective in engaging users and encouraging them to click on the links provided. My next steps would be to analyze the specific components of Campaign A to understand what drove the higher engagement, such as the email subject line, graphics, or call-to-action. I would also recommend further testing to confirm these results over multiple iterations and different user segments to ensure that the observed difference wasn’t due to external factors or variances in the audience groups. If the results remain consistent, I would consider applying the successful elements of Campaign A to other marketing materials and strategies to potentially improve overall marketing effectiveness.
Difficulty: Basic
Non-technical data science interview questions
Communication with stakeholders
Question: Data science often involves collaboration with various stakeholders. Can you describe a situation where you had to explain a complex data science concept or finding to a non-technical audience? What approach did you take?
Sample answer: In one of my previous roles, I was responsible for presenting monthly performance metrics derived from our predictive models to the marketing team, who were not familiar with data science. To effectively communicate these complex concepts, I used metaphors and analogies related to common experiences, like predicting the weather, to explain how predictive models work. I also created visualizations and dashboards that illustrated the data in an intuitive way, showing trends and patterns without getting into the statistical details.
Difficulty: Basic
Ethical considerations
Question: Data science can sometimes present ethical challenges. Can you talk about a time when you faced an ethical dilemma in your work? How did you handle it?
Sample answer: At a previous job, I was part of a project where we were using customer data to optimize marketing strategies. We identified that much of the data could be considered sensitive, as it involved personal customer behaviors and preferences. I raised my concerns about potential privacy issues with the project team and suggested that we conduct a thorough review of the data usage policies and ensure compliance with data protection regulations. To address this, we worked with the legal and compliance teams to modify our data collection and processing practices to ensure that they were transparent and secure.
Difficulty: Basic
Leadership and project management
Question: Imagine you are leading a data science team that is working on a high-impact project with tight deadlines. Halfway through, you realize the project goals are not aligned with the latest business objectives due to changes at the executive level. How would you handle this situation to ensure the project’s success and maintain team motivation?
Sample answer: In such a scenario, my first step would be to immediately engage with stakeholders to clarify the new business objectives and gather as much information as possible about the changes at the executive level. I would then hold a meeting with my team to transparently communicate the changes and the reasons behind them, ensuring to address any concerns and gather input on how to realign our goals with the new objectives. To minimize disruption, I’d work on adjusting the project plan collaboratively, identifying which parts of our current work can be repurposed or adapted. Throughout this process, I would emphasize the importance of our adaptability as a team to new challenges, recognizing contributions already made, and motivating the team by highlighting the critical nature of our alignment with the company’s strategic goals. Regular check-ins would be scheduled to ensure the project remains on track and to provide support where needed, and I’d maintain an open dialogue to keep the team engaged and motivated.
Difficulty: Advanced
Next steps & resources
Data science is a lucrative, in-demand field that blends analytical thinking with the power to craft compelling narratives from data. While securing a data science role can be challenging—especially in today’s competitive job market—being well-prepared for the interview can significantly improve your chances.
Whether you’re aiming for a career as a data scientist or just looking to enhance your data skills, the first step is simple and free: enroll in some CodeSignal Learn courses. You’ll be tackling real-world data problems and refining your technical skills in no time. Start your journey with CodeSignal Learn for free today and build your expertise in data science—or explore countless other technical skill areas.